# Token-Oriented Object Notation (TOON)
[](https://github.com/toon-format/toon/actions)
[](https://www.npmjs.com/package/@toon-format/toon)
[](https://github.com/toon-format/spec)
[](https://www.npmjs.com/package/@toon-format/toon)
[](./LICENSE)
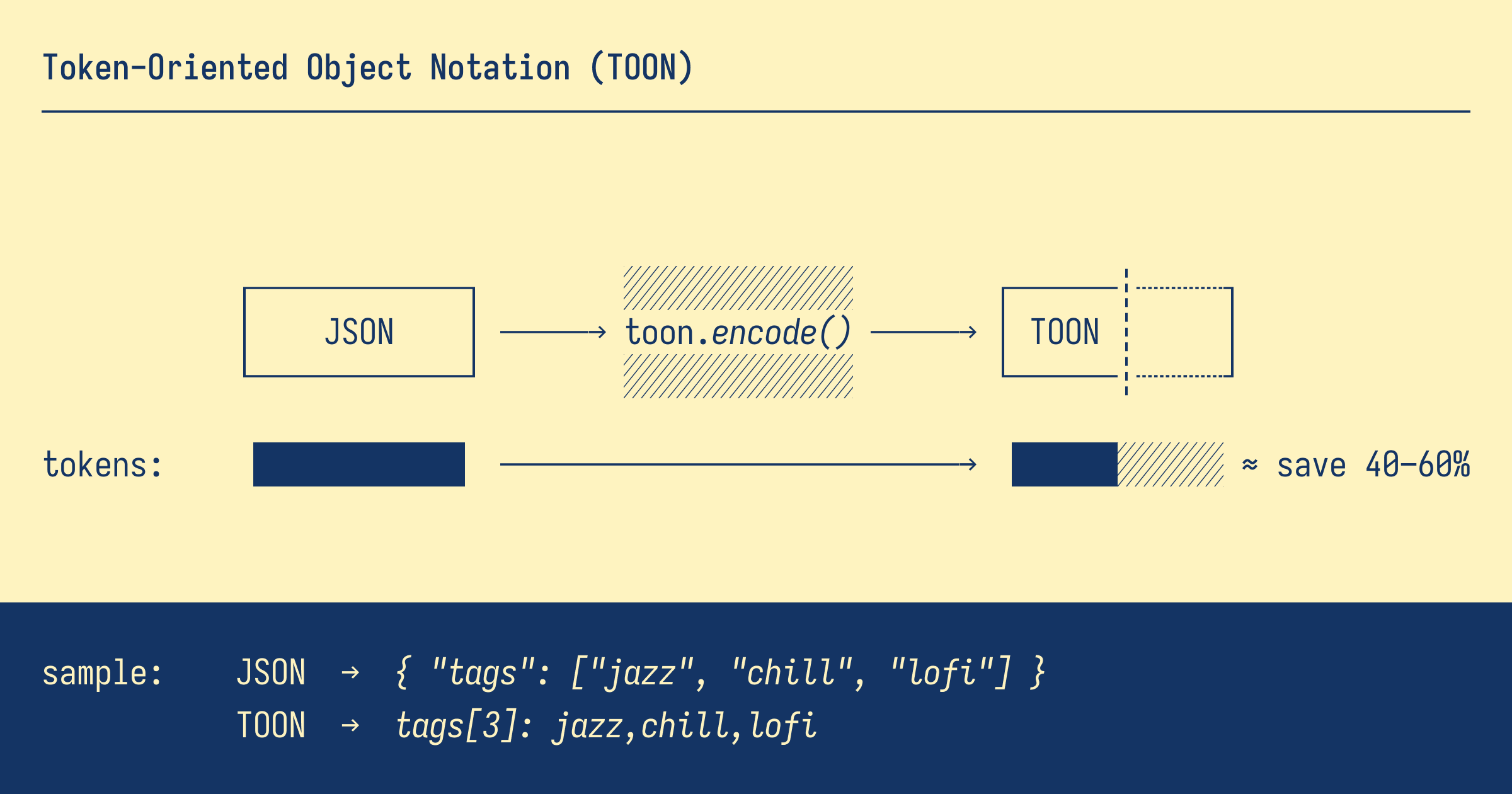
**Token-Oriented Object Notation** is a compact, human-readable serialization format designed for passing structured data to Large Language Models with significantly reduced token usage. It's intended for LLM input, not output.
TOON's sweet spot is **uniform arrays of objects** – multiple fields per row, same structure across items. It borrows YAML's indentation-based structure for nested objects and CSV's tabular format for uniform data rows, then optimizes both for token efficiency in LLM contexts. For deeply nested or non-uniform data, JSON may be more efficient.
> [!TIP]
> Think of TOON as a translation layer: use JSON programmatically, convert to TOON for LLM input.
## Table of Contents
- [Why TOON?](#why-toon)
- [Key Features](#key-features)
- [Benchmarks](#benchmarks)
- [📋 Full Specification](https://github.com/toon-format/spec/blob/main/SPEC.md)
- [Installation & Quick Start](#installation--quick-start)
- [CLI](#cli)
- [Format Overview](#format-overview)
- [API](#api)
- [Using TOON in LLM Prompts](#using-toon-in-llm-prompts)
- [Notes and Limitations](#notes-and-limitations)
- [Syntax Cheatsheet](#syntax-cheatsheet)
- [Other Implementations](#other-implementations)
## Why TOON?
AI is becoming cheaper and more accessible, but larger context windows allow for larger data inputs as well. **LLM tokens still cost money** – and standard JSON is verbose and token-expensive:
```json
{
"users": [
{ "id": 1, "name": "Alice", "role": "admin" },
{ "id": 2, "name": "Bob", "role": "user" }
]
}
```
TOON conveys the same information with **fewer tokens**:
```
users[2]{id,name,role}:
1,Alice,admin
2,Bob,user
```
Why create a new format?
For small payloads, JSON/CSV/YAML work fine. TOON's value emerges at scale: when you're making hundreds of LLM calls with uniform tabular data, eliminating repeated keys compounds savings significantly. If token costs matter to your use case, TOON reduces them. If not, stick with what works.
## Key Features
- 💸 **Token-efficient:** typically 30–60% fewer tokens than JSON
- 🤿 **LLM-friendly guardrails:** explicit lengths and fields enable validation
- 🍱 **Minimal syntax:** removes redundant punctuation (braces, brackets, most quotes)
- 📐 **Indentation-based structure:** like YAML, uses whitespace instead of braces
- 🧺 **Tabular arrays:** declare keys once, stream data as rows
## Benchmarks
> [!TIP]
> Try the interactive [Format Tokenization Playground](https://www.curiouslychase.com/playground/format-tokenization-exploration) to compare token usage across CSV, JSON, YAML, and TOON with your own data.
The benchmarks test datasets that favor TOON's strengths (uniform tabular data). Real-world performance depends heavily on your data structure.
### Token Efficiency
```
⭐ GitHub Repositories ██████████████░░░░░░░░░░░ 8,745 tokens
vs JSON (-42.3%) 15,145
vs JSON compact (-23.7%) 11,455
vs YAML (-33.4%) 13,129
vs XML (-48.8%) 17,095
📈 Daily Analytics ██████████░░░░░░░░░░░░░░░ 4,507 tokens
vs JSON (-58.9%) 10,977
vs JSON compact (-35.7%) 7,013
vs YAML (-48.8%) 8,810
vs XML (-65.7%) 13,128
🛒 E-Commerce Order ████████████████░░░░░░░░░ 166 tokens
vs JSON (-35.4%) 257
vs JSON compact (-2.9%) 171
vs YAML (-15.7%) 197
vs XML (-38.7%) 271
─────────────────────────────────────────────────────────────────────
Total ██████████████░░░░░░░░░░░ 13,418 tokens
vs JSON (-49.1%) 26,379
vs JSON compact (-28.0%) 18,639
vs YAML (-39.4%) 22,136
vs XML (-56.0%) 30,494
```
Show detailed examples
#### ⭐ GitHub Repositories
**Configuration:** Top 100 GitHub repositories with stars, forks, and metadata
**Savings:** 6,400 tokens (42.3% reduction vs JSON)
**JSON** (15,145 tokens):
```json
{
"repositories": [
{
"id": 28457823,
"name": "freeCodeCamp",
"repo": "freeCodeCamp/freeCodeCamp",
"description": "freeCodeCamp.org's open-source codebase and curriculum. Learn math, programming,…",
"createdAt": "2014-12-24T17:49:19Z",
"updatedAt": "2025-10-28T11:58:08Z",
"pushedAt": "2025-10-28T10:17:16Z",
"stars": 430886,
"watchers": 8583,
"forks": 42146,
"defaultBranch": "main"
},
{
"id": 132750724,
"name": "build-your-own-x",
"repo": "codecrafters-io/build-your-own-x",
"description": "Master programming by recreating your favorite technologies from scratch.",
"createdAt": "2018-05-09T12:03:18Z",
"updatedAt": "2025-10-28T12:37:11Z",
"pushedAt": "2025-10-10T18:45:01Z",
"stars": 430877,
"watchers": 6332,
"forks": 40453,
"defaultBranch": "master"
},
{
"id": 21737465,
"name": "awesome",
"repo": "sindresorhus/awesome",
"description": "😎 Awesome lists about all kinds of interesting topics",
"createdAt": "2014-07-11T13:42:37Z",
"updatedAt": "2025-10-28T12:40:21Z",
"pushedAt": "2025-10-27T17:57:31Z",
"stars": 410052,
"watchers": 8017,
"forks": 32029,
"defaultBranch": "main"
}
]
}
```
**TOON** (8,745 tokens):
```
repositories[3]{id,name,repo,description,createdAt,updatedAt,pushedAt,stars,watchers,forks,defaultBranch}:
28457823,freeCodeCamp,freeCodeCamp/freeCodeCamp,"freeCodeCamp.org's open-source codebase and curriculum. Learn math, programming,…","2014-12-24T17:49:19Z","2025-10-28T11:58:08Z","2025-10-28T10:17:16Z",430886,8583,42146,main
132750724,build-your-own-x,codecrafters-io/build-your-own-x,Master programming by recreating your favorite technologies from scratch.,"2018-05-09T12:03:18Z","2025-10-28T12:37:11Z","2025-10-10T18:45:01Z",430877,6332,40453,master
21737465,awesome,sindresorhus/awesome,😎 Awesome lists about all kinds of interesting topics,"2014-07-11T13:42:37Z","2025-10-28T12:40:21Z","2025-10-27T17:57:31Z",410052,8017,32029,main
```
---
#### 📈 Daily Analytics
**Configuration:** 180 days of web metrics (views, clicks, conversions, revenue)
**Savings:** 6,470 tokens (58.9% reduction vs JSON)
**JSON** (10,977 tokens):
```json
{
"metrics": [
{
"date": "2025-01-01",
"views": 6890,
"clicks": 401,
"conversions": 23,
"revenue": 6015.59,
"bounceRate": 0.63
},
{
"date": "2025-01-02",
"views": 6940,
"clicks": 323,
"conversions": 37,
"revenue": 9086.44,
"bounceRate": 0.36
},
{
"date": "2025-01-03",
"views": 4390,
"clicks": 346,
"conversions": 26,
"revenue": 6360.75,
"bounceRate": 0.48
},
{
"date": "2025-01-04",
"views": 3429,
"clicks": 231,
"conversions": 13,
"revenue": 2360.96,
"bounceRate": 0.65
},
{
"date": "2025-01-05",
"views": 5804,
"clicks": 186,
"conversions": 22,
"revenue": 2535.96,
"bounceRate": 0.37
}
]
}
```
**TOON** (4,507 tokens):
```
metrics[5]{date,views,clicks,conversions,revenue,bounceRate}:
2025-01-01,6890,401,23,6015.59,0.63
2025-01-02,6940,323,37,9086.44,0.36
2025-01-03,4390,346,26,6360.75,0.48
2025-01-04,3429,231,13,2360.96,0.65
2025-01-05,5804,186,22,2535.96,0.37
```
> [!NOTE]
> Token savings are measured against formatted JSON (2-space indentation) as the primary baseline. Additional comparisons include compact JSON (minified), YAML, and XML to provide a comprehensive view across common data formats. Measured with [`gpt-tokenizer`](https://github.com/niieani/gpt-tokenizer) using `o200k_base` encoding (GPT-5 tokenizer). Actual savings vary by model and tokenizer.
### Retrieval Accuracy
Accuracy across **4 LLMs** on 154 data retrieval questions:
```
gpt-5-nano
→ TOON ███████████████████░ 96.1% (148/154)
CSV ██████████████████░░ 91.6% (141/154)
YAML ██████████████████░░ 91.6% (141/154)
JSON compact ██████████████████░░ 91.6% (141/154)
XML █████████████████░░░ 87.0% (134/154)
JSON █████████████████░░░ 86.4% (133/154)
claude-haiku-4-5-20251001
JSON ██████████░░░░░░░░░░ 50.0% (77/154)
YAML ██████████░░░░░░░░░░ 49.4% (76/154)
→ TOON ██████████░░░░░░░░░░ 48.7% (75/154)
XML ██████████░░░░░░░░░░ 48.1% (74/154)
CSV █████████░░░░░░░░░░░ 47.4% (73/154)
JSON compact █████████░░░░░░░░░░░ 44.2% (68/154)
gemini-2.5-flash
CSV ██████████████████░░ 87.7% (135/154)
XML ██████████████████░░ 87.7% (135/154)
→ TOON █████████████████░░░ 86.4% (133/154)
YAML ████████████████░░░░ 79.9% (123/154)
JSON compact ████████████████░░░░ 79.9% (123/154)
JSON ███████████████░░░░░ 76.6% (118/154)
grok-4-fast-non-reasoning
→ TOON ██████████░░░░░░░░░░ 49.4% (76/154)
JSON ██████████░░░░░░░░░░ 48.7% (75/154)
XML █████████░░░░░░░░░░░ 46.1% (71/154)
YAML █████████░░░░░░░░░░░ 46.1% (71/154)
JSON compact █████████░░░░░░░░░░░ 45.5% (70/154)
CSV █████████░░░░░░░░░░░ 44.2% (68/154)
```
**Key tradeoff:** TOON achieves **70.1% accuracy** (vs JSON's 65.4%) while using **46.3% fewer tokens** on these datasets.
Performance by dataset and model
#### Performance by Dataset
##### Uniform employee records (TOON optimal format)
| Format | Accuracy | Tokens | Correct/Total |
| ------ | -------- | ------ | ------------- |
| `csv` | 65.5% | 2,337 | 131/200 |
| `toon` | 67.5% | 2,483 | 135/200 |
| `json-compact` | 65.5% | 3,943 | 131/200 |
| `yaml` | 68.5% | 4,969 | 137/200 |
| `xml` | 69.5% | 7,314 | 139/200 |
| `json-pretty` | 64.5% | 6,347 | 129/200 |
##### E-commerce orders with nested structures
| Format | Accuracy | Tokens | Correct/Total |
| ------ | -------- | ------ | ------------- |
| `toon` | 78.8% | 5,967 | 126/160 |
| `csv` | 76.3% | 6,735 | 122/160 |
| `json-compact` | 70.6% | 5,962 | 113/160 |
| `yaml` | 72.5% | 7,328 | 116/160 |
| `json-pretty` | 76.9% | 9,694 | 123/160 |
| `xml` | 73.1% | 10,992 | 117/160 |
##### Time-series analytics data
| Format | Accuracy | Tokens | Correct/Total |
| ------ | -------- | ------ | ------------- |
| `toon` | 68.4% | 1,515 | 93/136 |
| `csv` | 65.4% | 1,393 | 89/136 |
| `json-compact` | 64.7% | 2,341 | 88/136 |
| `yaml` | 66.2% | 2,938 | 90/136 |
| `json-pretty` | 64.7% | 3,665 | 88/136 |
| `xml` | 66.9% | 4,376 | 91/136 |
##### Top 100 GitHub repositories
| Format | Accuracy | Tokens | Correct/Total |
| ------ | -------- | ------ | ------------- |
| `toon` | 65.0% | 8,745 | 78/120 |
| `csv` | 62.5% | 8,513 | 75/120 |
| `json-compact` | 58.3% | 11,455 | 70/120 |
| `yaml` | 56.7% | 13,129 | 68/120 |
| `xml` | 55.8% | 17,095 | 67/120 |
| `json-pretty` | 52.5% | 15,145 | 63/120 |
#### Performance by Model
##### gpt-5-nano
| Format | Accuracy | Correct/Total |
| ------ | -------- | ------------- |
| `toon` | 96.1% | 148/154 |
| `csv` | 91.6% | 141/154 |
| `yaml` | 91.6% | 141/154 |
| `json-compact` | 91.6% | 141/154 |
| `xml` | 87.0% | 134/154 |
| `json-pretty` | 86.4% | 133/154 |
##### claude-haiku-4-5-20251001
| Format | Accuracy | Correct/Total |
| ------ | -------- | ------------- |
| `json-pretty` | 50.0% | 77/154 |
| `yaml` | 49.4% | 76/154 |
| `toon` | 48.7% | 75/154 |
| `xml` | 48.1% | 74/154 |
| `csv` | 47.4% | 73/154 |
| `json-compact` | 44.2% | 68/154 |
##### gemini-2.5-flash
| Format | Accuracy | Correct/Total |
| ------ | -------- | ------------- |
| `csv` | 87.7% | 135/154 |
| `xml` | 87.7% | 135/154 |
| `toon` | 86.4% | 133/154 |
| `yaml` | 79.9% | 123/154 |
| `json-compact` | 79.9% | 123/154 |
| `json-pretty` | 76.6% | 118/154 |
##### grok-4-fast-non-reasoning
| Format | Accuracy | Correct/Total |
| ------ | -------- | ------------- |
| `toon` | 49.4% | 76/154 |
| `json-pretty` | 48.7% | 75/154 |
| `xml` | 46.1% | 71/154 |
| `yaml` | 46.1% | 71/154 |
| `json-compact` | 45.5% | 70/154 |
| `csv` | 44.2% | 68/154 |
How the benchmark works
#### What's Being Measured
This benchmark tests **LLM comprehension and data retrieval accuracy** across different input formats. Each LLM receives formatted data and must answer questions about it (this does **not** test model's ability to generate TOON output).
#### Datasets Tested
Four datasets designed to test different structural patterns (all contain arrays of uniform objects, TOON's optimal format):
1. **Tabular** (100 employee records): Uniform objects with identical fields – optimal for TOON's tabular format.
2. **Nested** (50 e-commerce orders): Complex structures with nested customer objects and item arrays.
3. **Analytics** (60 days of metrics): Time-series data with dates and numeric values.
4. **GitHub** (100 repositories): Real-world data from top GitHub repos by stars.
#### Question Types
154 questions are generated dynamically across three categories:
- **Field retrieval (40%)**: Direct value lookups or values that can be read straight off a record (including booleans and simple counts such as array lengths)
- Example: "What is Alice's salary?" → `75000`
- Example: "How many items are in order ORD-0042?" → `3`
- Example: "What is the customer name for order ORD-0042?" → `John Doe`
- **Aggregation (32%)**: Dataset-level totals and averages plus single-condition filters (counts, sums, min/max comparisons)
- Example: "How many employees work in Engineering?" → `17`
- Example: "What is the total revenue across all orders?" → `45123.50`
- Example: "How many employees have salary > 80000?" → `23`
- **Filtering (28%)**: Multi-condition queries requiring compound logic (AND constraints across fields)
- Example: "How many employees in Sales have salary > 80000?" → `5`
- Example: "How many active employees have more than 10 years of experience?" → `8`
#### Evaluation Process
1. **Format conversion**: Each dataset is converted to all 6 formats (TOON, CSV, XML, YAML, JSON, JSON compact).
2. **Query LLM**: Each model receives formatted data + question in a prompt and extracts the answer.
3. **Validate with LLM-as-judge**: `gpt-5-nano` validates if the answer is semantically correct (e.g., `50000` = `$50,000`, `Engineering` = `engineering`, `2025-01-01` = `January 1, 2025`).
#### Models & Configuration
- **Models tested**: `gpt-5-nano`, `claude-haiku-4-5-20251001`, `gemini-2.5-flash`, `grok-4-fast-non-reasoning`
- **Token counting**: Using `gpt-tokenizer` with `o200k_base` encoding (GPT-5 tokenizer)
- **Temperature**: Not set (models use their defaults)
- **Total evaluations**: 154 questions × 6 formats × 4 models = 3,696 LLM calls
## Installation & Quick Start
```bash
# npm
npm install @toon-format/toon
# pnpm
pnpm add @toon-format/toon
# yarn
yarn add @toon-format/toon
```
**Example usage:**
```ts
import { encode } from '@toon-format/toon'
const data = {
users: [
{ id: 1, name: 'Alice', role: 'admin' },
{ id: 2, name: 'Bob', role: 'user' }
]
}
console.log(encode(data))
// users[2]{id,name,role}:
// 1,Alice,admin
// 2,Bob,user
```
## CLI
Command-line tool for converting between JSON and TOON formats.
### Usage
```bash
npx @toon-format/cli [options]
```
**Auto-detection:** The CLI automatically detects the operation based on file extension (`.json` → encode, `.toon` → decode).
```bash
# Encode JSON to TOON (auto-detected)
npx @toon-format/cli input.json -o output.toon
# Decode TOON to JSON (auto-detected)
npx @toon-format/cli data.toon -o output.json
# Output to stdout
npx @toon-format/cli input.json
```
### Options
| Option | Description |
| ------ | ----------- |
| `-o, --output ` | Output file path (prints to stdout if omitted) |
| `-e, --encode` | Force encode mode (overrides auto-detection) |
| `-d, --decode` | Force decode mode (overrides auto-detection) |
| `--delimiter ` | Array delimiter: `,` (comma), `\t` (tab), `\|` (pipe) |
| `--indent ` | Indentation size (default: `2`) |
| `--length-marker` | Add `#` prefix to array lengths (e.g., `items[#3]`) |
| `--stats` | Show token count estimates and savings (encode only) |
| `--no-strict` | Disable strict validation when decoding |
### Examples
```bash
# Show token savings when encoding
npx @toon-format/cli data.json --stats -o output.toon
# Tab-separated output (often more token-efficient)
npx @toon-format/cli data.json --delimiter "\t" -o output.toon
# Pipe-separated with length markers
npx @toon-format/cli data.json --delimiter "|" --length-marker -o output.toon
# Lenient decoding (skip validation)
npx @toon-format/cli data.toon --no-strict -o output.json
```
## Format Overview
> [!NOTE]
> For precise formatting rules and implementation details, see the [full specification](https://github.com/toon-format/spec).
### Objects
Simple objects with primitive values:
```ts
encode({
id: 123,
name: 'Ada',
active: true
})
```
```
id: 123
name: Ada
active: true
```
Nested objects:
```ts
encode({
user: {
id: 123,
name: 'Ada'
}
})
```
```
user:
id: 123
name: Ada
```
### Arrays
> [!TIP]
> TOON includes the array length in brackets (e.g., `items[3]`). When using comma delimiters (default), the delimiter is implicit. When using tab or pipe delimiters, the delimiter is explicitly shown in the header (e.g., `tags[2|]` or `[2 ]`). This encoding helps LLMs identify the delimiter and track the number of elements, reducing errors when generating or validating structured output.
#### Primitive Arrays (Inline)
```ts
encode({
tags: ['admin', 'ops', 'dev']
})
```
```
tags[3]: admin,ops,dev
```
#### Arrays of Objects (Tabular)
When all objects share the same primitive fields, TOON uses an efficient **tabular format**:
```ts
encode({
items: [
{ sku: 'A1', qty: 2, price: 9.99 },
{ sku: 'B2', qty: 1, price: 14.5 }
]
})
```
```
items[2]{sku,qty,price}:
A1,2,9.99
B2,1,14.5
```
**Tabular formatting applies recursively:** nested arrays of objects (whether as object properties or inside list items) also use tabular format if they meet the same requirements.
```ts
encode({
items: [
{
users: [
{ id: 1, name: 'Ada' },
{ id: 2, name: 'Bob' }
],
status: 'active'
}
]
})
```
```
items[1]:
- users[2]{id,name}:
1,Ada
2,Bob
status: active
```
#### Mixed and Non-Uniform Arrays
Arrays that don't meet the tabular requirements use list format:
```
items[3]:
- 1
- a: 1
- text
```
When objects appear in list format, the first field is placed on the hyphen line:
```
items[2]:
- id: 1
name: First
- id: 2
name: Second
extra: true
```
> [!NOTE]
> **Nested array indentation:** When the first field of a list item is an array (primitive, tabular, or nested), its contents are indented two spaces under the header line, and subsequent fields of the same object appear at that same indentation level. This remains unambiguous because list items begin with `"- "`, tabular arrays declare a fixed row count in their header, and object fields contain `":"`.
#### Arrays of Arrays
When you have arrays containing primitive inner arrays:
```ts
encode({
pairs: [
[1, 2],
[3, 4]
]
})
```
```
pairs[2]:
- [2]: 1,2
- [2]: 3,4
```
#### Empty Arrays and Objects
Empty containers have special representations:
```ts
encode({ items: [] }) // items[0]:
encode([]) // [0]:
encode({}) // (empty output)
encode({ config: {} }) // config:
```
### Quoting Rules
TOON quotes strings **only when necessary** to maximize token efficiency:
- Inner spaces are allowed; leading or trailing spaces force quotes.
- Unicode and emoji are safe unquoted.
- Quotes and control characters are escaped with backslash.
> [!NOTE]
> When using alternative delimiters (tab or pipe), the quoting rules adapt automatically. Strings containing the active delimiter will be quoted, while other delimiters remain safe.
#### Object Keys and Field Names
Keys are unquoted if they match the identifier pattern: start with a letter or underscore, followed by letters, digits, underscores, or dots (e.g., `id`, `userName`, `user_name`, `user.name`, `_private`). All other keys must be quoted (e.g., `"user name"`, `"order-id"`, `"123"`, `"order:id"`, `""`).
#### String Values
String values are quoted when any of the following is true:
| Condition | Examples |
|---|---|
| Empty string | `""` |
| Leading or trailing spaces | `" padded "`, `" "` |
| Contains active delimiter, colon, quote, backslash, or control chars | `"a,b"` (comma), `"a\tb"` (tab), `"a\|b"` (pipe), `"a:b"`, `"say \"hi\""`, `"C:\\Users"`, `"line1\\nline2"` |
| Looks like boolean/number/null | `"true"`, `"false"`, `"null"`, `"42"`, `"-3.14"`, `"1e-6"`, `"05"` |
| Starts with `"- "` (list-like) | `"- item"` |
| Looks like structural token | `"[5]"`, `"{key}"`, `"[3]: x,y"` |
**Examples of unquoted strings:** Unicode and emoji are safe (`hello 👋 world`), as are strings with inner spaces (`hello world`).
> [!IMPORTANT]
> **Delimiter-aware quoting:** Unquoted strings never contain `:` or the active delimiter. This makes TOON reliably parseable with simple heuristics: split key/value on first `: `, and split array values on the delimiter declared in the array header. When using tab or pipe delimiters, commas don't need quoting – only the active delimiter triggers quoting for both array values and object values.
### Type Conversions
Some non-JSON types are automatically normalized for LLM-safe output:
| Input | Output |
|---|---|
| Number (finite) | Decimal form, no scientific notation (e.g., `-0` → `0`, `1e6` → `1000000`) |
| Number (`NaN`, `±Infinity`) | `null` |
| `BigInt` | If within safe integer range: converted to number. Otherwise: quoted decimal string (e.g., `"9007199254740993"`) |
| `Date` | ISO string in quotes (e.g., `"2025-01-01T00:00:00.000Z"`) |
| `undefined` | `null` |
| `function` | `null` |
| `symbol` | `null` |
## API
### `encode(value: unknown, options?: EncodeOptions): string`
Converts any JSON-serializable value to TOON format.
**Parameters:**
- `value` – Any JSON-serializable value (object, array, primitive, or nested structure). Non-JSON-serializable values (functions, symbols, undefined, non-finite numbers) are converted to `null`. Dates are converted to ISO strings, and BigInts are emitted as decimal integers (no quotes).
- `options` – Optional encoding options:
- `indent?: number` – Number of spaces per indentation level (default: `2`)
- `delimiter?: ',' | '\t' | '|'` – Delimiter for array values and tabular rows (default: `','`)
- `lengthMarker?: '#' | false` – Optional marker to prefix array lengths (default: `false`)
**Returns:**
A TOON-formatted string with no trailing newline or spaces.
**Example:**
```ts
import { encode } from '@toon-format/toon'
const items = [
{ sku: 'A1', qty: 2, price: 9.99 },
{ sku: 'B2', qty: 1, price: 14.5 }
]
encode({ items })
```
**Output:**
```
items[2]{sku,qty,price}:
A1,2,9.99
B2,1,14.5
```
#### Delimiter Options
The `delimiter` option allows you to choose between comma (default), tab, or pipe delimiters for array values and tabular rows. Alternative delimiters can provide additional token savings in specific contexts.
##### Tab Delimiter (`\t`)
Using tab delimiters instead of commas can reduce token count further, especially for tabular data:
```ts
const data = {
items: [
{ sku: 'A1', name: 'Widget', qty: 2, price: 9.99 },
{ sku: 'B2', name: 'Gadget', qty: 1, price: 14.5 }
]
}
encode(data, { delimiter: '\t' })
```
**Output:**
```
items[2 ]{sku name qty price}:
A1 Widget 2 9.99
B2 Gadget 1 14.5
```
**Benefits:**
- Tabs are single characters and often tokenize more efficiently than commas.
- Tabs rarely appear in natural text, reducing the need for quote-escaping.
- The delimiter is explicitly encoded in the array header, making it self-descriptive.
**Considerations:**
- Some terminals and editors may collapse or expand tabs visually.
- String values containing tabs will still require quoting.
##### Pipe Delimiter (`|`)
Pipe delimiters offer a middle ground between commas and tabs:
```ts
encode(data, { delimiter: '|' })
```
**Output:**
```
items[2|]{sku|name|qty|price}:
A1|Widget|2|9.99
B2|Gadget|1|14.5
```
#### Length Marker Option
The `lengthMarker` option adds an optional hash (`#`) prefix to array lengths to emphasize that the bracketed value represents a count, not an index:
```ts
const data = {
tags: ['reading', 'gaming', 'coding'],
items: [
{ sku: 'A1', qty: 2, price: 9.99 },
{ sku: 'B2', qty: 1, price: 14.5 },
],
}
console.log(
encode(data, { lengthMarker: '#' })
)
// tags[#3]: reading,gaming,coding
// items[#2]{sku,qty,price}:
// A1,2,9.99
// B2,1,14.5
// Custom delimiter with length marker
console.log(
encode(data, { lengthMarker: '#', delimiter: '|' })
)
// tags[#3|]: reading|gaming|coding
// items[#2|]{sku|qty|price}:
// A1|2|9.99
// B2|1|14.5
```
### `decode(input: string, options?: DecodeOptions): JsonValue`
Converts a TOON-formatted string back to JavaScript values.
**Parameters:**
- `input` – A TOON-formatted string to parse
- `options` – Optional decoding options:
- `indent?: number` – Expected number of spaces per indentation level (default: `2`)
- `strict?: boolean` – Enable strict validation (default: `true`)
**Returns:**
A JavaScript value (object, array, or primitive) representing the parsed TOON data.
**Example:**
```ts
import { decode } from '@toon-format/toon'
const toon = `
items[2]{sku,qty,price}:
A1,2,9.99
B2,1,14.5
`
const data = decode(toon)
// {
// items: [
// { sku: 'A1', qty: 2, price: 9.99 },
// { sku: 'B2', qty: 1, price: 14.5 }
// ]
// }
```
**Strict Mode:**
By default, the decoder validates input strictly:
- **Invalid escape sequences**: Throws on `"\x"`, unterminated strings.
- **Syntax errors**: Throws on missing colons, malformed headers.
- **Array length mismatches**: Throws when declared length doesn't match actual count.
- **Delimiter mismatches**: Throws when row delimiters don't match header.
## Notes and Limitations
- Format familiarity and structure matter as much as token count. TOON's tabular format requires arrays of objects with identical keys and primitive values only. When this doesn't hold (due to mixed types, non-uniform objects, or nested structures), TOON switches to list format where JSON can be more efficient at scale.
- **TOON excels at:** Uniform arrays of objects (same fields, primitive values), especially large datasets with consistent structure.
- **JSON is better for:** Non-uniform data, deeply nested structures, and objects with varying field sets.
- **Token counts vary by tokenizer and model.** Benchmarks use a GPT-style tokenizer (cl100k/o200k); actual savings will differ with other models (e.g., [SentencePiece](https://github.com/google/sentencepiece)).
- **TOON is designed for LLM input** where human readability and token efficiency matter. It's **not** a drop-in replacement for JSON in APIs or storage.
## Using TOON in LLM Prompts
TOON works best when you show the format instead of describing it. The structure is self-documenting – models parse it naturally once they see the pattern.
### Sending TOON to LLMs (Input)
Wrap your encoded data in a fenced code block (label it \`\`\`toon for clarity). The indentation and headers are usually enough – models treat it like familiar YAML or CSV. The explicit length markers (`[N]`) and field headers (`{field1,field2}`) help the model track structure, especially for large tables.
### Generating TOON from LLMs (Output)
For output, be more explicit. When you want the model to **generate** TOON:
- **Show the expected header** (`users[N]{id,name,role}:`). The model fills rows instead of repeating keys, reducing generation errors.
- **State the rules:** 2-space indent, no trailing spaces, `[N]` matches row count.
Here's a prompt that works for both reading and generating:
````
Data is in TOON format (2-space indent, arrays show length and fields).
```toon
users[3]{id,name,role,lastLogin}:
1,Alice,admin,2025-01-15T10:30:00Z
2,Bob,user,2025-01-14T15:22:00Z
3,Charlie,user,2025-01-13T09:45:00Z
```
Task: Return only users with role "user" as TOON. Use the same header. Set [N] to match the row count. Output only the code block.
````
> [!TIP]
> For large uniform tables, use `encode(data, { delimiter: '\t' })` and tell the model "fields are tab-separated." Tabs often tokenize better than commas and reduce the need for quote-escaping.
## Syntax Cheatsheet
Show format examples
```
// Object
{ id: 1, name: 'Ada' } → id: 1
name: Ada
// Nested object
{ user: { id: 1 } } → user:
id: 1
// Primitive array (inline)
{ tags: ['foo', 'bar'] } → tags[2]: foo,bar
// Tabular array (uniform objects)
{ items: [ → items[2]{id,qty}:
{ id: 1, qty: 5 }, 1,5
{ id: 2, qty: 3 } 2,3
]}
// Mixed / non-uniform (list)
{ items: [1, { a: 1 }, 'x'] } → items[3]:
- 1
- a: 1
- x
// Array of arrays
{ pairs: [[1, 2], [3, 4]] } → pairs[2]:
- [2]: 1,2
- [2]: 3,4
// Root array
['x', 'y'] → [2]: x,y
// Empty containers
{} → (empty output)
{ items: [] } → items[0]:
// Special quoting
{ note: 'hello, world' } → note: "hello, world"
{ items: ['true', true] } → items[2]: "true",true
```
## Other Implementations
> [!NOTE]
> When implementing TOON in other languages, please follow the [specification](https://github.com/toon-format/spec/blob/main/SPEC.md) (currently v1.3) to ensure compatibility across implementations. The [conformance tests](https://github.com/toon-format/spec/tree/main/tests) provide language-agnostic test fixtures that validate implementations across any language.
- **.NET:** [ToonSharp](https://github.com/0xZunia/ToonSharp)
- **Crystal:** [toon-crystal](https://github.com/mamantoha/toon-crystal)
- **Dart:** [toon](https://github.com/wisamidris77/toon)
- **Elixir:** [toon_ex](https://github.com/kentaro/toon_ex)
- **Gleam:** [toon_codec](https://github.com/axelbellec/toon_codec)
- **Go:** [gotoon](https://github.com/alpkeskin/gotoon)
- **Java:** [JToon](https://github.com/felipestanzani/JToon)
- **OCaml:** [ocaml-toon](https://github.com/davesnx/ocaml-toon)
- **PHP:** [toon-php](https://github.com/HelgeSverre/toon-php)
- **Python:** [python-toon](https://github.com/xaviviro/python-toon) or [pytoon](https://github.com/bpradana/pytoon)
- **Ruby:** [toon-ruby](https://github.com/andrepcg/toon-ruby)
- **Rust:** [rtoon](https://github.com/shreyasbhat0/rtoon)
- **Swift:** [TOONEncoder](https://github.com/mattt/TOONEncoder)
## License
[MIT](./LICENSE) License © 2025-PRESENT [Johann Schopplich](https://github.com/johannschopplich)